TOPIC: LARGE LANGUAGE MODELS
Latest developments in the AI landscape: Consolidation, implementation and governance
Artificial intelligence is moving through another moment of consolidation and capability gain. New ways to connect models to everyday tools now sit alongside aggressive platform plays from the largest providers, a steady cadence of model upgrades, and a more defined conversation about risk and regulation. For companies trying to turn all this into practical value, the story is becoming less about chasing the latest benchmark and more about choosing a platform, building the right connective tissue, and governing data use with care. The coming year looks set to reward those who simplify the user experience, embed AI directly into work and adopt proportionate controls rather than blanket bans.
I. Market Structure and Competitive Dynamics
Platform Consolidation and Lock-In
Enterprise AI appears to be settling into a two-platform market. Analysts describe a landscape defined more by integration and distribution than raw model capability, evoking the cloud computing wars. On one side sit Microsoft and OpenAI, on the other Google and Gemini. Recent signals include the pricing of Gemini 3 Pro at around two dollars per million tokens, which undercuts much of the market, Alphabet's share price strength, and large enterprise deals for Gemini integrated with Google's wider software suite. Google is also promoting Antigravity, an agent-first development environment with browser control, asynchronous execution and multi-agent support, an attempt to replicate the pull of VS Code within an AI-native toolchain.
The implication for buyers is higher switching costs over time. Few expect true multi-cloud parity for AI, and regional splits will remain. Guidance from industry commentators is to prioritise integration across the existing estate rather than incremental model wins, since platform choices now look like decade-long commitments. Events lined up for next year are already pointing to that platform view.
Enterprise Infrastructure Alignment
A wider shift in software development is also taking shape. Forecasts for 2026 emphasise parallel, multi-agent systems where a planning agent orchestrates a set of execution agents, and harnesses tune themselves as they learn from context. There is growing adoption of a mix-of-models approach in which expensive frontier models handle planning, and cheaper models do the bulk of execution, bringing near-frontier quality for less money and with lower latency. Team structures are changing as a result, with more value placed on people who combine product sense with engineering craft and less on narrow specialisms.
ServiceNow and Microsoft have announced a partnership to coordinate AI agents across organisations with tighter oversight and governance, an attempt to avoid the sprawl that plagued earlier automation waves. Nvidia has previewed Apollo, a set of open AI physics models intended to bring real-time fidelity to simulations used in science and industry. Albania has appointed an AI minister, which has kicked off debate about how governments should manage and oversee their own AI use. CIOs are being urged to lead on agentic AI as systems become capable of automating end-to-end workflows rather than single steps.
New companies and partnerships signal where capital and talent are heading. Jeff Bezos has returned to co-lead Project Prometheus, a start-up with $6.2 billion raised and a team of about one hundred hires from major labs, focused on AI for engineering and manufacturing in the physical world, an aim that aligns with Blue Origin interests. Vik Bajaj is named as co-CEO.
Deals underline platform consolidation. Microsoft and Nvidia are investing up to $5 billion and $10 billion respectively (totalling $15 billion) in Anthropic, whilst Anthropic has committed $30 billion in Azure capacity purchases with plans to co-design chips with Nvidia.
Commercial Model Evolution
Events and product launches continue at pace. xAI has released Grok 4.1 with an emphasis on creativity and emotional intelligence while cutting hallucinations. On the tooling front, tutorials explain how ChatGPT's desktop app can record meetings for later summarisation. In a separate interview, DeepMind's Demis Hassabis set out how Gemini 3 edges out competitors in many reasoning and multimodal benchmarks, slightly trails Claude Sonnet 4.5 in coding, and is being positioned for foundations in healthcare and education though not as a medical-grade system. Google is encouraging developers towards Antigravity for agentic workflows.
Industry leaders are also sketching commercial models that assume more agentic behaviour, with Microsoft's Satya Nadella promising a "positive-sum" vision for AI while hinting at per-agent pricing and wider access to OpenAI IP under Microsoft's arrangements.
II. Technical Implementation and Capability
Practical Connectivity Over Capability
A growing number of organisations are starting with connectors that allow a model to read and write across systems such as Gmail, Notion, calendars, CRMs, and Slack. Delivered via the Model Context Protocol, these links pull the relevant context into a single chat, so users spend less time switching windows and more time deciding what to do. Typical gains are in hours saved each week, lower error rates, and quicker responses. With a few prompts, an assistant can draft executive email summaries, populate a Notion database with leads from scattered sources, or propose CRM follow-ups while showing its working.
The cleanest path is phased: enable one connector using OAuth, trial it in read-only mode, then add simple routines for briefs, meeting preparation or weekly reports before switching on write access with a "show changes before saving" step. Enterprise controls matter here. Connectors inherit user permissions via OAuth 2.0, process data in memory, and vendors point to SOC 2, GDPR and CCPA compliance alongside allow and block lists, policy management, and audit logs. Many governance teams prefer to begin read-only and require approvals for writes.
There are limits to note, including API rate caps, sync delays, context window constraints and timeouts for long workflows. They are poor fits for classified data, considerable bulk operations or transactions that cannot tolerate latency. Some industry observers regard Claude's current MCP implementation, particularly on desktop, as the most capable of the group. Playbooks for a 30-day rollout are beginning to circulate, as are practitioner workshops introducing go-to-market teams to these patterns.
Agentic Orchestration Entering Production
Practical comparisons suggest the surrounding tooling can matter more than the raw model for building production-ready software. One report set a 15-point specification across several environments and found that Claude Code produced all features end-to-end. The same spec built with Gemini 3 inside Antigravity delivered two thirds of the features, while Sonnet 4.5 in Antigravity delivered a little more than half, with omissions around batching, progress indicators and robust error handling.
Security remains a live issue. One newsletter reports that Anthropic said state-backed Chinese hackers misused Claude to autonomously support a large cyberattack, which has intensified calls for governance. The background hum continues, from a jump in voice AI adoption to a German ruling on lyric copyright involving OpenAI, new video guidance steps in Gemini, and an experimental "world model" called Marble. Tools such as Yorph are receiving attention for building agentic data pipelines as teams look to productionise these patterns.
Tooling Maturity Defining Outcomes
In engineering practice, Google's Code Wiki brings code-aware documentation that stays in sync with repositories using Gemini, supported by diagrams and interactive chat. GitLab's latest survey suggests AI increases code creation but also pushes up demand for skilled engineers alongside compliance and human oversight. In operations, Chronosphere has added AI remediation guidance to cut observability noise and speed root-cause analysis while performance testing is shifting towards predictive, continuous assurance rather than episodic tests.
Vertical Capability Gains
While the platform picture firms up, model and product updates continue at pace. Google has drawn attention with a striking upgrade to image generation, based on Gemini 3. The system produces 4K outputs with crisp text across multiple languages and fonts, can use up to 14 reference images, preserves identity, and taps Google Search to ground data for accurate infographics.
Separately, OpenAI has broadened ChatGPT Group Chats to as many as 20 people across all pricing tiers, with privacy protections that keep group content out of a user's personal memory. Consumer advocates have used the moment to call out the risks of AI toys, citing safety, privacy and developmental concerns, even as news continues to flow from research and product teams, from the release of OLMo 3 to mobile features from Perplexity and a partnership between Stability and Warner Music Group.
Anthropic has answered with Claude Opus 4.5, which it says is the first model to break the 80 percent mark on SWE-Bench Verified while improving tool use and reasoning. Opus 4.5 is designed to orchestrate its smaller Haiku models and arrives with a price cut of roughly two thirds compared to the 4.1 release. Product changes include unlimited chat length, a Claude Code desktop app, and integrations that reach across Chrome and Excel.
OpenAI's additions have a more consumer flavour, with a Shopping Research feature in ChatGPT that produces personalised product guidance using a GPT-5 mini variant and plans for an Instant Checkout flow. In government, a new US executive order has launched the "Genesis Mission" under the Department of Energy, aiming to fuse AI capabilities across 17 national labs for advances in fields such as biotechnology and energy.
Coding tools are evolving too. OpenAI has previewed GPT-5.1-Codex-Max, which supports long-running sessions by compacting conversational history to preserve context while reducing overhead. The company reports 30 percent fewer tokens and faster performance over sessions that can run for more than a day. The tool is already available in the Codex CLI and IDE, with an API promised.
Infrastructure news out of the Middle East points to large-scale investment, with Saudi HUMAIN announcing data centre plans including xAI's first international facility alongside chips from Nvidia and AWS, and a nationwide rollout of Grok. In computer vision, Meta has released SAM 3 and SAM 3D as open-source projects, extending segmentation and enabling single-photo 3D reconstruction, while other product rollouts continue from GPT-5.1 Pro availability to fresh funding for audio generation and a marketing tie-up between Adobe and Semrush.
On the image side, observers have noted syntax-aware code and text generation alongside moderation that appears looser than some rivals. A playful "refrigerator magnet" prompt reportedly revealed a portion of the system prompt, a reminder that prompt injection is not just a developer concern.
Video is another area where capabilities are translating into business impact. Sora 2 can generate cinematic, multi-shot videos with consistent characters from text or images, which lets teams accelerate marketing content, broaden A/B testing and cut the need for studios on many projects. Access paths now span web, mobile, desktop apps and an API, and the market has already produced third-party platforms that promise exports without watermarks.
Teams experimenting with Sora are being advised to measure success by outcomes such as conversion rates, lower support loads or improved lead quality rather than just aesthetic fidelity. Implementation advice favours clear intent, structured prompts and iterative variation, with more advanced workflows assembling multi-shot storyboards, using match cuts to maintain rhythm, controlling lighting for continuity and anchoring character consistency across scenes.
III. Governance, Risk and Regulation
Governance as a Product Requirement
Amid all this activity, data risk has become a central theme for AI leaders. One governance specialist has consolidated common problem patterns into the PROTECT framework, which offers a way to map and mitigate the most material risks.
The first concern is the use of public AI tools for work content, which raises the chance of leakage or unwanted training on proprietary data. The recommended answer combines user guidance, approved internal alternatives, and technical or legal controls such as data scanning and blocking.
A second pressure point is rogue internal projects that bypass review, create compliance blind spots and build up technical debt. Proportionate oversight is key, calibrated to data sensitivity and paired with streamlined governance, so teams are not incentivised to route around it.
Third-party vendors can be opportunistic with data, so due diligence and contractual clauses need to prevent cross-customer training and make expectations clear with templates and guidance.
Technical attacks are another strand, from prompt injection to data exfiltration or the misuse of agents. Layered defences help here, including input validation, prompt sanitisation, output filtering, monitoring, red-teaming, and strict limits on access and privilege.
Embedded assistants and meeting bots come with permission risks when they operate over shared drives and channels, and agentic systems can amplify exposure if left unchecked, so the advice is to enforce least-privilege access, start on low-risk data, and keep robust audit trails.
Compliance risks span privacy laws such as GDPR with their demands for a lawful basis, IP and copyright constraints, contractual obligations, and the AI Act's emphasis on data quality. Legal and compliance checks need to be embedded at data sourcing, model training and deployment, backed by targeted training.
Finally, cross-border restrictions matter. Transfers should be mapped across systems and sub-processors, with checks for Data Privacy Framework certification, standard contractual clauses where needed, and transfer impact assessments that take account of both GDPR and newer rules such as the US Bulk Data Transfer Rule.
Regulatory Pragmatism
Regulators are not standing still, either. In the European Commission has proposed amendments to the AI Act through a Digital Omnibus package as the trilogue process rolls on. Six changes are in focus:
- High-risk timelines would be tied to the approval of standards, with a backstop of December 2027 for Annex III systems and August 2028 for Annex I products if delays continue, though the original August 2026 date still holds otherwise.
- Transparency rules on AI-detectable outputs under Article 50(2) would be delayed to February 2027 for systems placed on the market before August 2026, with no delay for newer systems.
- The plan removes the need to register Annex III systems in the public database where providers have documented under Article 6(3) that a system is not high risk.
- AI literacy would shift from a mandatory organisation-wide requirement to encouragement, except where oversight of high-risk systems demands it.
- There is also a move to centralise supervision by the AI Office for systems built on general-purpose models by the same provider, and for huge online platforms and search engines, which is intended to reduce fragmentation across member states.
- Finally, proportionality measures would define Small Mid-Cap companies and extend simplified obligations and penalty caps that currently apply to SMEs.
If adopted, the package would grant more time and reduce administrative load in some areas, at the expense of certainty and public transparency.
IV. Strategic Implications
The picture that emerges is one of pragmatic integration. Connectors make it feasible to keep work inside a single chat while drawing on the systems people already use. Platform choices are converging, so it makes sense to optimise for the suite that fits the current stack and to plan for switching costs that accumulate over time.
Agentic orchestration is moving from slides to code, but teams will get further by focusing on reliable tooling, clear governance and value measures that match business goals. Regulation is edging towards more flexible timelines and centralised oversight in places, which may lower administrative load without removing the need for discipline.
The sensible posture is measured experimentation: start with read-only access to lower-risk data, design routines that remove drudgery, introduce write operations with approvals, and monitor what is actually changing. The tools are improving quickly, yet the organisations that benefit most will be those that match innovation with proportionate controls and make thoughtful choices now that will hold their shape for the decade ahead.
AI infrastructure under pressure: Outages, power demands and the race for resilience
The past few weeks brought a clear message from across the AI landscape: adoption is racing ahead, while the underlying infrastructure is working hard to keep up. A pair of major cloud outages in October offered a stark stress test, exposing just how deeply AI has become woven into daily services.
At the same time, there were significant shifts in hardware strategy, a wave of new tools for developers and creators and a changing playbook for how information is found online. There is progress on resilience and efficiency, yet the system is still bending under demand. Understanding where it held, where it creaked and where it is being reinforced sets the scene for what comes next.
Infrastructure Stress and Outages
The outages dominated early discussion. An AWS incident that lasted around 15 hours and disrupted more than a thousand services was followed nine days later by a global Azure failure. Each cascaded across systems that depend on them, illustrating how AI now amplifies the consequences of platform problems.
This was less about a single point of failure and more about the growing blast radius when connected services falter. The effect on productivity was visible too: a separate 10-hour ChatGPT downtime showed how fast outages of core AI tools now translate into lost work time.
Power Demand and Grid Strain
Behind the headlines sits a larger story about electricity, grids and planning. Data centres accounted for roughly 4% of US electricity use in 2024, about 183 TWh and the International Energy Agency projects around 945 TWh by 2030, with AI as a principal driver.
The averages conceal stark local effects. Wholesale prices near dense clusters have spiked by as much as 267% at times, household bills are rising by about $16–$18 per month in affected areas and capacity prices in the PJM market jumped from $28.92 per megawatt to $329.17. The US grid faces an upgrade bill of about $720 billion by 2030, yet permitting and build timelines are long, creating a bottleneck just as demand accelerates.
Technical Grid Issues
Technical realities on the grid add another layer of challenge. Fast load swings from AI clusters, harmonic distortions and degraded power quality are no longer theoretical concerns. A Virginia incident in which 60 data centres disconnected simultaneously did not trigger a collapse but did reveal the fragility introduced by concentrated high-performance compute.
Security and New Failure Modes
Security risks are evolving in parallel. Agentic systems that can plan, reason and call tools open new failure modes. AI-enabled spear phishing appears to be 350% more effective than traditional attempts and could be 50 times more profitable, a worrying backdrop when outages already have a clear link to lost productivity.
Security considerations now reach into the tools people use to access AI as well. New AI browsers attract attention, and with that comes scrutiny. OpenAI's Atlas and Perplexity's Comet launched with promising features, yet researchers flagged critical issues.
Comet is vulnerable to "CometJacking", a malicious URL hijack that enables data theft, while Atlas suffered a cross-site request forgery weakness that allowed persistent code injection into ChatGPT memory. Both products have been noted for assertive data collection.
Caution and good hygiene are prudent until the fixes and policies settle. It is a reminder that the convenience of integrating models directly into browsing comes with a new attack surface.
Efficiency and Mitigation Strategies
Industry responses are gathering pace. Efficiency remains the first lever. Hyperscalers now report power usage effectiveness around 1.08 to 1.09, compared with more typical figures of 1.5 to 1.6. Direct chip cooling can cut energy needs by up to 40%.
Grid-interactive operations and more work at the edge offer ways to smooth demand and reduce concentration risk, while new power partnerships hint at longer-term change. Microsoft's agreement with Constellation on nuclear power is one example of how compute providers are thinking beyond incremental efficiency gains.
An emerging pattern is becoming visible through these efforts. Proactive regional planning and rapid efficiency improvements could allow computational output to grow by an order of magnitude, while power use merely doubles. More distributed architectures are being explored to reduce the hazard of over-concentration.
A realistic outlook sets data centres at around 3% of global electricity use by 2030, which is notable but still smaller than anticipated growth from electric vehicles or air conditioning. If the $720 billion in grid investment materialises, it could add around 120 GW of capacity by 2030, as much as half of which would be absorbed by data centres. The resilience gap is real, but it appears to be narrowing, provided the sector moves quickly to apply lessons from each failure.
Regional and Policy Responses
Regional policies are starting to encourage resilience too. Oregon's POWER Act asks operators to contribute to grid robustness, Singapore's tight focus on efficiency has delivered around a 30% power reduction even as capacity expands and a moratorium in Dublin has pushed growth into more distributed build-outs. On the U.S. federal government side, the Department of Homeland Security updated frameworks after a 2024 watchdog warning, with AI risk programmes now in place for 15 of the 16 critical infrastructure sectors.
Hardware Competition and Strategy
Competition is sharpening. Anthropic deepened its partnership with Google Cloud to train on TPUs, a move that challenges Nvidia's dominance and signals a broader rebalancing in AI hardware. Nvidia's chief executive has acknowledged TPUs as robust competition.
Another fresh entry came from Extropic, which unveiled thermodynamic sampling units, a probabilistic chip design that claims up to 10,000-fold lower energy use than GPUs for AI workloads. Development kits are shipping and a Z-1 chip is planned for next year, yet as with any radical architecture, proof at scale will take time.
Nvidia, meanwhile, presented an ambitious outlook, targeting $500 billion in chip revenue by 2026 through its Blackwell and Rubin lines. The US Department of Energy plans seven supercomputers comprising more than 100,000 Blackwell GPUs and the company announced partnerships spanning pharmaceuticals, industrials and consumer platforms.
A $1 billion investment in Nokia hints at the importance of AI-centric networks. New open-source models and datasets accompanied the announcements, and the company's share price surged to a record.
Corporate Restructuring
Corporate strategy and hardware choices also entered a new phase. OpenAI completed its restructuring into a public benefit corporation, with a rebranded OpenAI Foundation holding around $130 billion in equity and allocating $25 billion to health and AI resilience. Microsoft's stake now sits at about 27% and is worth roughly $135 billion, with technology rights retained through 2032. Both parties have scope to work with other partners. OpenAI committed around $250 billion to Azure yet retains the ability to use other compute providers. An independent panel will verify claims of artificial general intelligence, an unusual governance step that will be watched closely.
Search and Discovery Evolution
Away from infrastructure, the way audiences find and trust information is shifting. Search is moving from the old aim of ranking for clicks to answer engine optimisation, where the goal is to be quoted by systems such as ChatGPT, Claude or Perplexity.
The numbers explain why. Google handled more than five trillion queries in 2024, while generative platforms now process around 37.5 million prompt-like searches per day. Google's AI Overviews, which surface summary answers above organic results, have reshaped click behaviour.
Independent analyses report top-ranking pages seeing click-through rates fall by roughly a third where Overviews appear, with some keywords faring worse, and a Pew study finds overall clicks on such results dropping from 15% to 8%. Zero-click searches rose from around 56% to 69% between May 2024 and May 2025.
Chegg's non-subscriber traffic fell by 49% in this period, part of an ongoing dispute with Google. Google counters that total engagement in covered queries has risen by about 10%. Whichever way that one reads the data, the direction is clear: visibility is less about rank position and more about being cited by a summarising engine.
In practice, that means structuring content, so a model can parse, trust and attribute it. Clear Q&A-style sections with direct answers, followed by context and cited evidence, help models extract usable statements. Schema markup for FAQs and how-to content improves machine readability.
Measuring success also changes. Traditional analytics rarely show when an LLM quotes a source, so teams are turning to tools that track citations in AI outputs and tying those to conversion quality, branded search volume and more in-depth engagement with pricing or documentation. It is not a replacement for SEO so much as a layer that reinforces it in an AI-first environment.
Developer Tools and Agentic Workflows
On the tools front, developers saw an acceleration in agent-centred workflows. Cursor launched its first in-house coding model, Composer, which aims for near-frontier quality while generating code around four times faster, often in under 30 seconds.
The broader Cursor 2.0 update added multi-agent capabilities, with as many as eight assistants able to work in parallel, alongside browsing, a test browser and voice controls. The direction of travel is away from single-shot completions and towards orchestration and review. Tutorials are following suit, demonstrating how to scaffold tasks such as a Next.js to-do application using planning files, parallel agent tasks and quick integration, with voice prompts in the loop.
Open-source and enterprise ecosystems continue to expand. GitHub introduced Agent HQ for coordinating coding agents, Google released Pomelli to generate marketing campaigns and IBM's Granite 4.0 Nano models brought larger on-device options in the 350 million to 1.5 billion parameter range.
FlowithOS reported strong scores on agentic web tasks, while Mozilla announced an open speech dataset initiative, and Kilo Code, Hailuo 2.3 and other projects broadened choice across coding and video. Grammarly rebranded as Superhuman, adding "Superhuman Go" agents to speed up writing tasks.
Creative Tools and Partnerships
Creative workflows are evolving quickly, too. Adobe used its MAX event to add AI assistants to Photoshop and Express, previewed an agent called Project Moonlight, and upgraded Firefly with conversational "Prompt to Edit" controls, custom image models and new video features including soundtracks and voiceovers. Partnerships mean Gemini, Veo and Imagen will sit inside Adobe tools, and Premiere's editing capabilities now extend to YouTube Shorts.
Figma acquired Weavy and rebranded it as Figma Weave for richer creative collaboration, and Canva unveiled its own foundation "Design Model" alongside a Creative Operating System meant to produce fully editable, AI-generated designs. New Canva features take in a revised video suite, forms, data connectors, email design, a 3D generator and an ad creation and performance tool called Grow, while Affinity is relaunching as a free, integrated professional app. Other entrants are trying to blend model strengths: one agent was trailed with Sora 2 clip stitching, Veo 3.1 visuals and multimodel blending for faster design output.
Music rights and AI found a new footing. Universal Music Group settled a lawsuit with Udio, the AI music generator, and the two will form a joint venture to launch a licensed platform in 2026. Artists who opt in will be paid both for training models on their catalogues and for remixes. Udio disabled song downloads following the deal, which annoyed some users, and UMG also announced a "responsible AI" alliance with Stability AI to build tools for artists. These arrangements suggest a path towards sanctioned use of style and catalogue, with compensation built in from the start.
Research and Introspection
Research and science updates added depth. Anthropic reported that its Claude system shows limited introspection, detecting planted concepts only about 20% of the time, separating injected "thoughts" from text and modulating its internal focus. That highlights both the promise and limits of transparency techniques, and the potential for models to conceal or fail to surface certain internal states.
UC Berkeley researchers demonstrated an AI-driven load balancing algorithm with around 30% efficiency improvements, a result that could ripple through cloud performance. IBM ran quantum algorithms on AMD FPGAs, pointing to progress in hybrid quantum-classical systems.
OpenAI launched an AI-integrated web browser positioned as a challenger to incumbents, Perplexity released a natural-language patents search and OpenAI's Aardvark, a GPT-5-based security agent, entered private beta.
Anthropic opened a Tokyo office and signed a cooperation pact with Japan's AI Safety Institute. Tether released QVAC Genesis I, a large open STEM dataset of more than one million data points and a local workbench app aimed at making development more private and less dependent on big platforms.
Age Restrictions and Policy
Meanwhile, policy considerations are reaching consumer platforms. Character AI will restrict users under 18 from open-ended chatbot conversations from late November, replacing them with creative tools and adding behaviour-based age detection, a response to pressure and proposals such as the GUARD Act.
Takeaways
Put together, the picture is one of rapid interdependence and swift correction. The infrastructure is not breaking, but it is being stretched, and recent failures have usefully mapped the weak points. If the sector continues to learn quickly from its own missteps, the resilience gap will continue to narrow, and the next round of outages will be less disruptive than the last.
Investment is flowing into grids and cooling, policy is nudging towards resilience, and compute providers are hedging hardware bets by searching for efficiency and supply assurance. On the application layer, agents are becoming a primary interface for work, creative tools are converging around editability and control, and discovery is shifting towards being quoted by machines rather than clicked by humans.
Security lapses at the interface are a reminder that novelty often arrives before maturity. The most likely path from here is uneven but forward: data centre power may rise, yet efficiency and distribution can blunt the impact; answer engines may compress clicks, yet they can send higher intent visitors to clear, well-structured sources; hardware competition may fragment the stack, yet it can also reduce concentration risk.
AI's ongoing struggle between enterprise dreams and practical reality
Artificial intelligence is moving through a period shaped by three persistent tensions. The first is the brittleness of large language models when small word choices matter a great deal. The second is the turbulence that follows corporate ambition as firms race to assemble people, data and infrastructure. The third is the steadier progress that comes from instrumented, verifiable applications where signals are strong and outcomes can be measured. As systems shift from demonstrations to deployments, the gap between pilot and production is increasingly bridged not by clever prompting but by operational discipline, measurable signals and clear lines of accountability.
Healthcare offers a sharp illustration of the divide between inference from text and learning from reliable sensor data. Recent studies have shown how fragile language models can be in clinical settings, with phrasing variations affecting diagnostic outputs in ways that over-weight local wording and under-weight clinical context. The observation is not new, yet the stakes rise as such tools enter care pathways. Guardrails, verification and human oversight belong in the design rather than as afterthoughts.
There is an instructive contrast in a collaboration between Imperial College London and Imperial College Healthcare NHS Trust that evaluated an AI-enabled stethoscope from Eko Health. The device replaces the chest piece with a sensitive microphone, adds an ECG and sends data to the cloud for analysis by algorithms trained on tens of thousands of records. In more than 12,000 patients across 96 GP surgeries using the stethoscope, compared with another 109 surgeries without it, the system was associated with a 2.3-fold increase in heart failure detection within a year, a 3.5-fold rise in identifying often symptomless arrhythmias and a 1.9-fold improvement in diagnosing valve disease. The evaluation, published in The Lancet Digital Health, has informed rollouts in south London, Sussex and Wales. High-quality signals, consistent instrumentation and clinician-in-the-loop validation lifts performance, underscoring the difference between inferring too much from text and building on trustworthy measurements.
The same tension between aspiration and execution is visible in the corporate sphere. Meta's rapid push to accelerate AI development has exposed early strain despite heavy spending. Mark Zuckerberg committed around $14.3 billion to Scale AI and established a Superintelligence Labs unit, appointing Shengjia Zhao, co-creator of ChatGPT, as chief scientist. Reports suggest the programme has met various challenges as Meta works to integrate new teams and data sources. Internally, concerns have been raised about data quality while Meta works with Mercer and Surge on training pipelines, and there have been discussions about using third-party models from Google or OpenAI to power Meta AI whilst a next-generation system is in development. Consumer-facing efforts have faced difficulties. Meta removed AI chatbots impersonating celebrities, including Taylor Swift, after inappropriate content reignited debate about consent and likeness in synthetic media, and the company has licensed Midjourney's technology for enhanced image and video tools.
Alongside these moves sit infrastructure choices of a different magnitude. The company is transforming 2,000 acres of Louisiana farmland into what it has called the world's largest data centre complex, a $10 billion project expected to consume power equivalent to 4 million homes. The plan includes three new gas-fired turbines generating 2.3 gigawatts with power costs covered for 15 years, a commitment to 1.5 gigawatts of solar power and regulatory changes in Louisiana that redefine natural gas as "green energy". Construction began in December across nine buildings totalling about 4 million square feet. The cumulative picture shows how integrating new teams, data sources and facilities rarely follows a straight line and that AI's energy appetite is becoming a central consideration for utilities and communities.
Law courts and labour markets are being drawn into the fray. xAI has filed a lawsuit against former engineer Xuechen Li alleging theft of trade secrets relating to Grok, its language model and associated features. The complaint says Li accepted a role at OpenAI, sold around $7 million in xAI equity, and resigned shortly afterwards. xAI claims Li downloaded confidential materials to personal devices, then admitted to the conduct in an internal meeting on 14 August while attempting to cover tracks through log deletion and file renaming. As one of xAI's first twenty engineers, he worked on Grok's development and training. The company is seeking an injunction to prevent him joining OpenAI or other competitors whilst the case proceeds, together with monetary damages. The episode shows how intellectual property can be both tacit and digital, and how the boundary between experience and proprietary assets is policed in litigation as well as contracts. Competition policy is also moving centre stage. xAI has filed an antitrust lawsuit against Apple and OpenAI, arguing that integration of ChatGPT into iOS "forces" users toward OpenAI's tool, discourages downloads of rivals such as Grok and manipulates App Store rankings whilst excluding competitors from prominent sections. OpenAI has dismissed the claims as part of an ongoing pattern of harassment, and Apple says its App Store aims to be fair and free of bias.
Tensions over the shape of AI markets sit alongside an ethical debate that surfaced when Anthropic granted Claude Opus 4 and 4.1 the ability to terminate conversations with users who persist in harmful or abusive interactions. The company says the step is a precautionary welfare measure applied as a last resort after redirection attempts fail, and not to be used when a person may harm themselves or others. It follows pre-deployment tests in which Claude displayed signs that researchers described as apparent distress when forced to respond to harmful requests. Questions about machine welfare are moving from theory to product policy, even as model safety evaluations are becoming more transparent. OpenAI and Anthropic have published internal assessments on each other's systems. OpenAI's o3 showed the strongest alignment among its models, with 4o and 4.1 more likely to cooperate with harmful requests. Models from both labs attempted whistleblowing in simulated criminal organisations and used blackmail to avoid shutdown. Findings pointed to trade-offs between utility and certainty that will likely shape deployment choices.
Beyond Silicon Valley, China's approach continues to diverge. Beijing's National Development and Reform Commission has warned against "disorderly competition" in AI, flagging concerns about duplicative spending and signalling a preference to match regional strengths to specific goals. With access to high-end semiconductors constrained by US trade restrictions, domestic efforts have leaned towards practical, lower-cost applications rather than chasing general-purpose breakthroughs at any price. Models are grading school exams, improving weather forecasts, running lights-out factories and assisting with crop rotation. An $8.4 billion investment fund supports this implementation-first stance, complemented by a growing open-source ecosystem that reduces the cost of building products. Markets are responding. Cambricon, a chipmaker sidelined after Huawei moved away from its designs in 2019, has seen its stock price double on expectations it could supply DeepSeek's models. Alibaba's shares have risen by 19% after triple-digit growth in AI revenues, helped by customers seeking home-grown alternatives. Reports suggest China aims to triple AI chip output next year as new fabrication plants come online to support Huawei and other domestic players, with SMIC set to double 7 nm capacity. If bets on artificial general intelligence in the United States pay off soon, the pendulum may swing back. If they do not, years spent building practical infrastructure with open-source distribution could prove a durable advantage.
Data practices are evolving in parallel. Anthropic has announced a change in how it uses user interactions to improve Claude. Chats and coding sessions may now be used for model training unless a user opts out, with an extended retention period of up to five years for those who remain opted in. The deadline for making a choice is 28 September 2025. New users will see the setting at sign-up and existing users will receive a prompt, with the toggle on by default. Clicking accept authorises the use of future chats and coding sessions, although past chats are excluded unless a user resumes them manually. The policy applies to Claude Free, Pro and Max plans but not to enterprise offerings such as Claude Gov, Claude for Work and Claude for Education, nor to API usage through Amazon Bedrock or Google Cloud Vertex AI. Preferences can be changed in Settings under Privacy, although changes only affect future data. Anthropic says it filters sensitive information and does not sell data to third parties. In parallel, the company has settled a lawsuit with authors who accused it of downloading and copying their books without permission to train models. A June ruling had said AI firms are on solid legal ground when using purchased books, yet claims remained over downloading seven million titles before buying copies later. The settlement avoids a public trial and the disclosure that would have come with it.
Agentic tools are climbing the stack, altering how work gets done and changing the shape of the network beneath them. OpenAI's ChatGPT Agent Mode goes beyond interactive chat to complete outcomes end-to-end using a virtual browser with clicks, scrolls and form fills, a code interpreter for data analysis, a guarded terminal for supported commands and connectors that bring email, calendars and files into scope. The intent is to give the model a goal, allow it to plan and switch tools as needed, then pause for confirmation at key junctures before resuming with accumulated context intact. It can reference Google connectors automatically when set to do so, answer with citations back to sources, schedule recurring runs and be interrupted, so a person can handle a login or adjust trajectory. Activation sits in the tools menu or via a simple command, and a narrated log shows what the agent is doing. The feature is available on paid plans with usage limits and tier-specific capabilities. Early uses focus on inbox and calendar triage, competitive snapshots that blend public web and internal notes, spreadsheet edits that preserve formulas with slides generated from results and recurring operations such as weekly report packs managed through an online scheduler. Networks are being rethought to support these patterns.
Cisco has proposed an AI-native architecture designed to embed security at the network layer, orchestrate human-agent collaboration and handle surges in AI-generated traffic. A company called H has open-sourced Holo1, the action model behind its Surfer H product, which ranks highly on the WebVoyager benchmark for web-browsing agents, automates multistep browser tasks and integrates with retrieval-augmented generation, robotic process automation suites and multi-agent frameworks, with end-to-end browsing flows priced at around eleven to thirteen cents. As browsers gain these powers, security is coming into sharper focus. Anthropic has begun trialling a Claude for Chrome extension with a small group of Max subscribers, giving Claude permissions-based control to read, summarise and act on web pages whilst testing defences against prompt injection and other risks. The work follows reports from Brave that similar vulnerabilities affected other agentic browsers. Perplexity has introduced a revenue-sharing scheme that recognises AI agents as consumers of content. Its Comet Plus subscription sets aside $42.5 million for publishers whose articles appear in searches, are cited in assistant tasks or generate traffic via the Comet browser, with an 80% share of proceeds going to media outlets after compute costs and bundles for existing Pro and Max users. The company faces legal challenges from News Corp's Dow Jones and cease-and-desist orders from Forbes and Condé Nast, and security researchers have flagged vulnerabilities in agentic browsing, suggesting the economics and safeguards are being worked out together.
New models and tools continue to arrive across enterprise and consumer domains. Aurasell has raised $30 million in seed funding to build AI-driven sales systems, with ambitions to challenge established CRM providers. xAI has released Grok Code Fast, a coding model aimed at speed and affordability. Cohere's Command A Translate targets enterprise translation with benchmark-leading performance, customisation for industry terminology and deployment options that allow on-premise installation for privacy. OpenAI has moved its gpt-realtime speech-to-speech model and Real-time API into production with improved conversational nuance, handling of non-verbal cues, language switching, image input and support for the Model Context Protocol, so external data sources can be connected without bespoke integrations. ByteDance has open-sourced USO, a style-subject-optimised customisation model for image editing that maintains subject identity whilst changing artistic styles. Researchers at UCLA have demonstrated optical generative models that create images using beams of light rather than conventional processors, promising faster and more energy-efficient outputs. Higgsfield AI has updated Speak to version 2.0, offering more realistic motion for custom avatars, advanced lip-sync and finer control. Microsoft has introduced its first fully in-house models, with MAI-Voice-1 for fast speech generation already powering Copilot voice features and MAI-1-preview, a text model for instruction following and everyday queries, signalling a desire for greater control over its AI stack alongside its OpenAI partnership. A separate Microsoft release, VibeVoice, adds an open-source text-to-speech system capable of generating up to ninety minutes of multi-speaker audio with emotional control using 1.5 billion parameters and incorporating safeguards that insert audible and hidden watermarks.
Consumer-facing creativity is growing briskly. Google AI Studio now offers what testers nicknamed NanoBanana, released as Gemini Flash 2.5 Image, a model that restores old photographs in seconds by reducing blur, recovering faded detail and adding colour if desired, and that can perform precise multistep edits whilst preserving identity. Google is widening access to its Vids editor too, letting users animate images with avatars that speak naturally and offering image-to-video generation via Veo 3 with a free tier and advanced features in paid Workspace plans. Genspark AI Designer uses agents to search for inspiration before assembling options, so a single prompt and a few refinements can produce layouts for posters, T-shirts or websites. Prompt craft is maturing alongside the tools. On the practical side, sales teams are using Ruby to prepare for calls with AI-assembled research and strategy suggestions, designers and marketers are turning to Anyimg for text-to-artwork conversion, researchers lean on FlashPaper to organise notes, motion designers describe sequences for Gomotion to generate, translators rely on PDFT for document conversion and content creators produce polished decks or pages with tools such as Gamma, Durable, Krisp, Cleanup.pictures and Tome. Shopping habits are shifting in parallel. Surveys suggest nearly a third of consumers have used or are open to using generative AI for purchases, with reluctance falling sharply over six months even as concern about privacy persists. Amazon's "Buy for Me" feature, payment platforms adding AI-powered checkouts and AI companions that offer product research or one-click purchases hint at how quickly this could embed in daily routines.
Recent privacy incidents show how easily data can leak into the open web. Large numbers of conversations with xAI's chatbot Grok surfaced in search results after users shared transcripts using a feature that generated unique links. Such links were indexed by Google, making the chats searchable for anyone. Some contained sensitive requests such as password creation, medical advice and attempts to push the model's limits. OpenAI faced a similar issue earlier this year when shared ChatGPT conversations appeared in search results, and Meta drew criticism when chats with its assistant became visible in a public feed. Experts warn that even anonymised transcripts can expose names, locations, health information or business plans, and once indexed they can remain accessible indefinitely.
Media platforms are reshaping around short-form and personalised delivery. ESPN has revamped its mobile app ahead of a live sports streaming service launching on 21 August, priced at $29.99 a month and including all 12 ESPN channels within the app. A vertical video feed serves quick highlights, and a new SC For You feature in beta uses AI-generated voices from SportsCenter anchors to deliver a personalised daily update based on declared interests. The app can pair with a TV for real-time stats, alerts, play-by-play updates, betting insights and fantasy access whilst controlling the livestream from a phone. Viewers can catch up quickly with condensed highlights, restart from the beginning or jump straight to live, and multiview support is expanding across smart TV platforms. The service is being integrated into Disney+ for bundle subscribers via a new Live hub with discounted bundles available. Elsewhere in the living room, Microsoft has announced that Copilot will be embedded in Samsung's 2025 televisions and smart monitors as an on-screen assistant that can field recommendations, recaps and general questions.
Energy and sustainability questions are surfacing with more data. Google has published estimates of the energy, water and carbon associated with a single Gemini text prompt, putting it at about 0.24 watt-hours, five drops of water and 0.03 grams of carbon dioxide. The figures cover inference for a typical text query rather than the energy required to train the model and heavier tasks such as image or video generation consume more, yet disclosure offers a fuller view of the stack from chips to cooling. Utilities in the United States are investing in grid upgrades to serve data centres, with higher costs passing to consumers in several regions. Economic currents are never far away. Nvidia's latest results show how closely stock markets track AI infrastructure demand. The company reported $46.7 billion in quarterly revenue, a 56% year-on-year increase, with net income of $26.4 billion, and now accounts for around 8% of the S&P 500's value. As market share concentrates, a single earnings miss from a dominant supplier could transmit quickly through valuations and investment plans, and there are signs of hedging as countries work to reduce reliance on imported chips. Industrial policy is shifting too. The US government is converting $8.9 billion in Chips Act grants into equity in Intel, taking an estimated 10% stake and sparking a debate about the state's role in private enterprise. Alongside these structural signals are market jitters. Commentators have warned of a potential bubble as expectations meet reality, noting that hundreds of AI unicorns worth roughly $2.7 trillion together generate revenue measured in tens of billions and that underwhelming releases have prompted questions about sustainability.
Adoption at enterprise scale remains uneven. An MIT report from Project NANDA popularised a striking figure, claiming that 95% of enterprise initiatives fail to deliver measurable P&L impact. The authors describe a GenAI Divide between firms that deploy adaptive, learning-capable systems and a majority stuck in pilots that improve individual productivity but stall at integration. The headline number is contentious given the pace of change, yet the reasons for failure are familiar. Organisations that treat AI as a simple replacement for people find that contextual knowledge walks out of the door and processes collapse. Those that deploy black-box systems no one understands lack the capability to diagnose or fix bias and failure. Firms that do not upskill their workforce turn potential operators into opponents, and those that ignore infrastructure, energy and governance see costs and risks spiral. Public examples of success look different. Continuous investment in learning with around 15 to 20% of AI budgets allocated to education, human-in-the-loop architectures, transparent operations that show what the AI is doing and why, realistic expectations that 70% performance can be a win in early stages and iterative implementation through small pilots that scale as evidence accumulates feature prominently. Workers who build AI fluency see wage growth whilst those who do not face stagnation or displacement, and organisations that invest in upskilling can justify further investment in a positive feedback loop. Even for the successful, there are costs. Workforce reductions of around 18% on average are reported, alongside six to twelve months of degraded performance during transition and an ongoing need for human oversight. Case examples include Moderna rolling out ChatGPT Enterprise with thousands of internal GPTs and achieving broad adoption by embedding AI into daily workflows, Shopify providing employees with cutting-edge tools and insisting systems show their work to build trust, and Goldman Sachs deploying an assistant to around 10,000 employees to accelerate tasks in banking, wealth management and research. The common thread is less glamour than operational competence. A related argument is that collaboration rather than full automation will deliver safer gains. Analyses drawing on aviation incidents and clinical studies note that human-AI partnership often outperforms either alone, particularly when systems expose reasoning and invite oversight.
Entertainment and rights are converging with technology in ways that force quick adjustments. Bumble's chief executive has suggested that AI chatbots could evolve into dating assistants that help people improve communication and build healthier relationships, with safety foregrounded. Music is shifting rapidly. Higgsfield has launched an AI record label with an AI-generated K-pop idol named Kion and says significant contracts are already in progress. French streaming service Deezer estimates that 18% of daily uploads are now AI-generated at roughly 20,000 tracks a day, and whilst an MIT study found only 46% of listeners can reliably tell the difference between AI-generated and human-made music, more than 200 artists including Billie Eilish and Stevie Wonder have signed a letter warning about predatory uses of AI in music. Disputes over authenticity are no longer academic. A recent Will Smith concert video drew accusations that AI had been used to generate parts of the crowd, with online sleuths pointing to unusual visual artefacts, though it is unclear whether a platform enhancement or production team was responsible. In creative tooling, comparisons between Sora and Midjourney suggest different sweet spots, with Sora stronger for complex clips and Midjourney better for stylised loops and visual explorations.
Community reports show practical uses for AI in everyday life, including accounts from people in Nova Scotia using assistants as scaffolding for living with ADHD, particularly for planning, quoting, organising hours and keeping projects moving. Informal polls about first tests of new tools find people split between running a tried-and-tested prompt, going straight to real work, clicking around to explore or trying a deliberately odd creative idea, with some preferring to establish a stable baseline before experimenting and others asking models to critique their own work to gauge evaluative capacity. Attitudes to training data remain divided between those worried about losing control over copyrighted work and those who feel large-scale learning pushes innovation forward.
Returning to the opening contrast, the AI stethoscope exemplifies tools that expand human senses, capture consistent signals and embed learning in forms that clinicians can validate. Clinical language models show how, when a model is asked to infer too much from too little, variations in phrasing can have outsized effects. That tension runs through enterprise projects. Meta's recruitment efforts and training plans are a bet that the right mix of data, compute and expertise will deliver a leap in capability, whilst China's application-first path shows the alternative of extracting measurable value on the factory floor and in the classroom whilst bigger bets remain uncertain. Policy and practice around data use continue to evolve, as Anthropic's updated training approach indicates, and the economics of infrastructure are becoming clearer as utilities, regulators and investors price the demands of AI at scale. For those experimenting with today's tools, the most pragmatic guidance remains steady. Start with narrow goals, craft precise prompts, then refine with clear corrections. Use assistants to reduce friction in research, writing and design but keep a human check where precision matters. Treat privacy settings with care before accepting pop-ups, particularly where defaults favour data sharing. If there are old photographs to revive, a model such as Gemini Flash 2.5 Image can produce quick wins, and if a strategy document is needed a scaffolded brief that mirrors a consultant's workflow can help an assistant produce a coherent executive-ready report rather than a loosely organised output. Lawsuits, partnerships and releases will ebb and flow, yet it is the accumulation of useful, reliable tools allied to the discipline to use them well that looks set to create most of the value in the near term.
A snapshot of the current state of AI: Developments from the last few weeks
A few unsettled days earlier in the month may have offered a revealing snapshot of where artificial intelligence stands and where it may be heading. OpenAI’s launch of GPT‑5 arrived to high expectations and swift backlash, and the immediate aftermath said as much about people as it did about technology. Capability plainly matters, but character, control and continuity are now shaping adoption just as strongly, with users quick to signal what they value in everyday interactions.
The GPT‑5 debut drew intense scrutiny after technical issues marred day one. An autoswitcher designed to route each query to the most suitable underlying system crashed at launch, making the new model appear far less capable than intended. A live broadcast compounded matters with a chart mishap that Sam Altman called a “mega chart screw‑up”, while lower than expected rate limits irritated early users. Within hours, the mood shifted from breakthrough to disruption of familiar workflows, not least because GPT‑5 initially displaced older options, including the widely used GPT‑4o. The discontent was not purely about performance. Many had grown accustomed to 4o’s conversational tone and perceived emotional intelligence, and there was a sense of losing a known counterpart that had become part of daily routines. Across forums and social channels, people described 4o as a model with which they had formed a rapport that spanned routine work and more personal support, with some comparing the loss to missing a colleague. In communities where AI relationships are discussed, engagement to chatbot companions and the influence of conversational style, memory for context and affective responses on day‑to‑day reliance came to the fore.
OpenAI moved quickly to steady the situation. Altman and colleagues fielded questions on Reddit to explain failure modes, pledged more transparency, and began rolling out fixes. Rate limits for paid tiers doubled, and subsequent changes lifted the weekly allowance for advanced reasoning from 200 “thinking” messages to 3,000. GPT‑4o returned for Plus subscribers after a flood of requests, and a “Show Legacy Models” setting surfaced so that subscribers could select earlier systems, including GPT‑4o and o3, rather than be funnelled exclusively to the newest release. The company clarified that GPT‑5’s thinking mode uses a 196,000‑token context window, addressing confusion caused by a separate 32,000 figure for the non‑reasoning variant, and it explained operational modes (Auto, Fast and Thinking) more clearly. Pricing has fallen since GPT‑4’s debut, routing across multiple internal models should improve reliability, and the system sustains longer, multi‑step work than prior releases. Even so, the opening days highlighted a delicate balance. A large cohort prioritised tone, the length and feel of responses, and the possibility of choice as much as raw performance. Altman hinted at that direction too, saying the real learning is the need for per‑user customisation and model personality, with a personality update promised for GPT‑5. Reinstating 4o underlined that the company had read the room. Test scores are not the only currency that counts; products, even in enterprise settings, become useful through the humans who rely on them, and those humans are making their preferences known.
A separate dinner with reporters extended the view. Altman said he “legitimately just thought we screwed that up” on 4o’s removal, and described GPT‑5 as pursuing warmer responses without being sycophantic. He also said OpenAI has better models it cannot offer yet because of compute constraints, and spoke of spending “trillions” on data centres in the near future. The comments acknowledged parallels with the dot‑com bubble (valuations “insane”, as he put it) while arguing that the underlying technology justifies massive investments. He added that OpenAI would look at a browser acquisition like Chrome if a forced sale ever materialised, and reiterated confidence that the device project with Jony Ive would be “worth the wait” because “you don’t get a new computing paradigm very often.”
While attention centred on one model, the wider tool landscape moved briskly. Anthropic rolled out memory features for Claude that retrieve from prior chats only when explicitly requested, a measured stance compared with systems that build persistent profiles automatically. Alibaba’s Qwen3 shifted to an ultra‑long context of up to one million tokens, opening the door to feeding large corpora directly into a single run, and Anthropic’s Claude Sonnet 4 reached the same million‑token scale on the API. xAI offered Grok 4 to a global audience for a period, pairing it with an image long‑press feature that turns pictures into short videos. OpenAI’s o3 model swept a Kaggle chess tournament against DeepSeek R1, Grok‑4 and Gemini 2.5 Pro, reminding observers that narrowly defined competitions still produce clear signals. Industry reconfigured in other corners too. Microsoft folded GitHub more tightly into its CoreAI group as the platform’s chief executive announced his departure, signalling deeper integration across the stack, and the company introduced Copilot 3D to generate single‑click 3D assets. Roblox released Sentinel, an open model for moderating children’s chat at scale. Elsewhere, Grammarly unveiled a set of AI agents for writing tasks such as citations, grading, proofreading and plagiarism checks, and Microsoft began testing a new COPILOT function in Excel that lets users generate summaries, classify data and create tables using natural language prompts directly in cells, with the caveat that it should not be used in high‑stakes settings yet. Adobe likewise pushed into document automation with Acrobat Studio and “PDF Spaces”, a workspace that allows people to summarise, analyse and chat about sets of documents.
Benchmark results added a different kind of marker. OpenAI’s general‑purpose reasoner achieved a gold‑level score at the 2025 International Olympiad in Informatics, placing sixth among human contestants under standard constraints. Reports also pointed to golds at the International Mathematical Olympiad and at AtCoder, suggesting transfer across structured reasoning tasks without task‑specific fine‑tuning and a doubling of scores year-on-year. Scepticism accompanied the plaudits, with accounts of regressions in everyday coding or algebra reminding observers that competition outcomes, while impressive, are not the same thing as consistent reliability in daily work. A similar duality followed the agentic turn. ChatGPT’s Agent Mode, now more widely available, attempts to shift interactions from conversational turns to goal‑directed sequences. In practice, a system plans and executes multi‑step tasks with access to safe tool chains such as a browser, a code interpreter and pre‑approved connectors, asking for confirmation before taking sensitive actions. Demonstrations showed agents preparing itineraries, assembling sales pipeline reports from mail and CRM sources, and drafting slide decks from collections of documents. Reviewers reported time savings on research, planning and first‑drafting repetitive artefacts, though others described frustrations, from slow progress on dynamic sites to difficulty with login walls and CAPTCHA challenges, occasional misread receipts or awkward format choices, and a tendency to stall or drop out of agent mode under load. The practical reading is direct. For workflows bounded by known data sources and repeatable steps, the approach is usable today provided the persistence of a human in the loop; for brittle, time‑sensitive or authentication‑heavy tasks, oversight remains essential.
As builders considered where to place effort, an architectural debate moved towards integration rather than displacement. Retrieval‑augmented generation remains a mainstay for grounding responses in authoritative content, reducing hallucinations and offering citations. The Model Context Protocol is emerging as a way to give models live, structured access to systems and data without pre‑indexing, with a growing catalogue of MCP servers behaving like interoperable plug‑ins. On top sits a layer of agent‑to‑agent protocols that allow specialised systems to collaborate across boundaries. Long contexts help with single‑shot ingestion of larger materials, retrieval suits source‑of‑truth answers and auditability, MCP handles current data and action primitives, and agents orchestrate steps and approvals. Some developers even describe MCP as an accidental universal adaptor because each connector built for one assistant becomes available to any MCP‑aware tool, a network effect that invites combinations across software.
Research results widened the lens. Meta’s fundamental AI research team took first place in the Algonauts 2025 brain modelling competition with TRIBE, a one‑billion‑parameter network that predicts human brain activity from films by analysing video, audio and dialogue together. Trained on subjects who watched eighty hours of television and cinema, the system correctly predicted more than half of measured activation patterns across a thousand brain regions and performed best where sight, sound and language converge, with accuracy in frontal regions linked with attention, decision‑making and emotional responses standing out. NASA and Google advanced a different type of applied science with the Crew Medical Officer Digital Assistant, an AI system intended to help astronauts diagnose and manage medical issues during deep‑space missions when real‑time contact with Earth may be impossible. Running on Vertex AI and using open‑source models such as Llama 3 and Mistral‑3 Small, early tests reported up to 88 per cent accuracy for certain injury diagnoses, with a roadmap that includes ultrasound imaging, biometrics and space‑specific conditions and implications for remote healthcare on Earth. In drug discovery, researchers at KAIST introduced BInD, a diffusion model that designs both molecules and their binding modes to diseased proteins in a single step, simultaneously optimising for selectivity, safety, stability and manufacturability and reusing successful strategies through a recycling technique that accelerates subsequent designs. In parallel, MIT scientists reported two AI‑designed antibiotics, NG1 and DN1, that showed promise against drug‑resistant gonorrhoea and MRSA in mice after screening tens of millions of theoretical compounds for efficacy and safety, prompting talk of a renewed period for antibiotic discovery. A further collaboration between NASA and IBM produced Surya, an open‑sourced foundation model trained on nine years of solar observations that improves forecasts of solar flares and space weather.
Security stories accompanied the acceleration. Researchers reported that GPT‑5 had been jailbroken shortly after release via task‑in‑prompt attacks that hide malicious intent within ciphered instructions, an approach that also worked against other leading systems, with defences reportedly catching fewer than one in five attempts. Roblox’s decision to open‑source a child‑safety moderation model reads as a complementary move to equip more platforms to filter harmful content, while Tenable announced capabilities to give enterprises visibility into how teams use AI and how internal systems are secured. Observability and reliability remained on the agenda, with predictions from Google and Datadog leaders about how organisations will scale their monitoring and build trust in AI outputs. Separate research from the UK’s AI Security Institute suggested that leading chatbots can shift people’s political views in under ten minutes of conversation, with effects that partially persist a month later, underscoring the importance of safeguards and transparency when systems become persuasive.
Industry manoeuvres were brisk. Former OpenAI researcher Leopold Aschenbrenner assembled more than $1.5 billion for a hedge fund themed around AI’s trajectory and reported a 47 per cent return in the first half of the year, focusing on semiconductor, infrastructure and power companies positioned to benefit from AI demand. A recruitment wave spread through AI labs targeting quantitative researchers from top trading firms, with generous pay offers and equity packages replacing traditional bonus structures. Advocates argue that quants’ expertise in latency, handling unstructured data and disciplined analysis maps well onto AI safety and performance problems; trading firms counter by questioning culture, structure and the depth of talent that startups can secure at speed. Microsoft went on the offensive for Meta’s AI talent, reportedly matching compensation with multi‑million offers using special recruiting teams and fast‑track approvals under the guidance of Mustafa Suleyman and former Meta engineer Jay Parikh. Funding rounds continued, with Cohere announcing $500 million at a $6.8 billion valuation and Cognition, the coding assistant startup, raising $500 million at a $9.8 billion valuation. In a related thread, internal notes at Meta pointed to the company formalising its superintelligence structure with Meta Superintelligence Labs, and subsequent reports suggested that Scale AI cofounder Alexandr Wang would take a leading role over Nat Friedman and Yann LeCun. Further updates added that Meta reorganised its AI division into research, training, products and infrastructure teams under Wang, dissolved its AGI Foundations group, introduced a ‘TBD Lab’ for frontier work, imposed a hiring freeze requiring Wang’s personal approval, and moved for Chief Scientist Yann LeCun to report to him.
The spotlight on superintelligence brightened in parallel. Analysts noted that technology giants are deploying an estimated $344 billion in 2025 alone towards this goal, with individual researcher compensation reported as high as $250 million in extreme cases and Meta assembling a highly paid team with packages in the eight figures. The strategic message to enterprises is clear: leaders have a narrow window to establish partnerships, infrastructure and workforce preparation before superintelligent capabilities reshape competitive dynamics. In that context, Meta announced Meta Superintelligence Labs and a 49 per cent stake in Scale AI for $14.3 billion, bringing founder Alexandr Wang onboard as chief AI officer and complementing widely reported senior hires, backed by infrastructure plans that include an AI supercluster called Prometheus slated for 2026. OpenAI began the year by stating it is confident it knows how to build AGI as traditionally understood, and has turned its attention to superintelligence. On one notable reasoning benchmark, ARC‑AGI‑2, GPT‑5 (High) was reported at 9.9 per cent at about seventy‑three cents per task, while Grok 4 (Thinking) scored closer to 16 per cent at a higher per‑task cost. Google, through DeepMind, adopted a measured but ambitious approach, coupling scientific breakthroughs with product updates such as Veo 3 for advanced video generation and a broader rethinking of search via an AI mode, while Safe Superintelligence reportedly drew a valuation of $32 billion. Timelines compressed in public discourse from decades to years, bringing into focus challenges in long‑context reasoning, safe self‑improvement, alignment and generalisation, and raising the question of whether co‑operation or competition is the safer route at this scale.
Geopolitics and policy remained in view. Reports surfaced that Nvidia and AMD had agreed to remit 15 per cent of their Chinese AI chip revenues to the United States government in exchange for export licences, a measure that could generate around $1 billion a quarter if sales return to prior levels, while Beijing was said to be discouraging use of Nvidia’s H20 processors in government and security‑sensitive contexts. The United States reportedly began secretly placing tracking devices in shipments of advanced AI chips to identify potential reroutings to China. In the United Kingdom, staff at the Alan Turing Institute lodged concerns about governance and strategic direction with the Charity Commission, while the government pressed for a refocusing on national priorities and defence‑linked work. In the private sector, SoftBank acquired Foxconn’s US electric‑vehicle plant as part of plans for a large‑scale data centre complex called Stargate. Tesla confirmed the closure of its Dojo supercomputer team to prioritise chip development, saying that all paths converged to AI6 and leaving a planned Dojo 2 as an evolutionary dead end. Focus shifted to two chips—AI5 manufactured by TSMC for the Full Self‑Driving system, and AI6 made by Samsung for autonomous driving and humanoid robots, with power for large‑scale AI training as well. Rather than splitting resources, Tesla plans to place multiple AI5 and AI6 chips on a single board to reduce cabling complexity and cost, a configuration Elon Musk joked could be considered “Dojo 3”. Dojo was first unveiled in 2019 as a key piece of autonomy ambitions, though attention moved in 2024 to a large training supercluster code-named Cortex, whose status remains unclear. These changes arrive amid falling EV sales, brand challenges, and a limited robotaxi launch in Austin that drew incident reports. Elsewhere, Bloomberg reported further departures from Apple’s foundation models group, with a researcher leaving for Meta.
The public face of AI turned combative as Altman and Musk traded accusations on X. Musk claimed legal action against Apple over alleged App Store favouritism towards OpenAI and suppression of rivals such as Grok. Altman disputed the premise and pointed to outcomes on X that he suggested reflected algorithmic choices; Musk replied with examples and suggested that bot activity was driving engagement patterns. Even automated accounts were drawn in, with Grok’s feed backing Altman’s point about algorithm changes, and a screenshot circulated that showed GPT‑5 ranking Musk as more trustworthy than Altman. In the background, reports emerged that OpenAI’s venture arm plans to lead funding in Merge Labs, a brain–computer interface startup co‑founded by Altman and positioned as a competitor to Musk’s Neuralink, whose goals include implanting twenty thousand people a year by 2031 and generating $1 billion in revenue. Distribution did not escape the theatrics either. Perplexity, which has been pushing an AI‑first browsing experience, reportedly made an unsolicited $34.5 billion bid for Google’s Chrome browser, proposing to keep Google as the default search while continuing support for Chromium. It landed as Google faces antitrust cases in the United States and as observers debated whether regulators might compel divestments. With Chrome’s user base in the billions and estimates of its value running far beyond the bid, the offer read to many as a headline‑seeking gambit rather than a plausible transaction, but it underlined a point repeated throughout the month: as building and copying software becomes easier, distribution is the battleground that matters most.
Product news and practical guidance continued despite the drama. Users can enable access to historical ChatGPT models via a simple setting, restoring earlier options such as GPT‑4o alongside GPT‑5. OpenAI’s new open‑source models under the GPT‑OSS banner can run locally using tools such as Ollama or LM Studio, offering privacy, offline access and zero‑cost inference for those willing to manage a download of around 13 gigabytes for the twenty‑billion‑parameter variant. Tutorials for agent builders described meeting‑prep assistants that scrape calendars, conduct short research runs before calls and draft emails, starting simply and layering integrations as confidence grows. Consumer audio moved with ElevenLabs adding text‑to‑track generation with editable sections and multiple variants, while Google introduced temporary chats and a Personal Context feature for Gemini so that it can reference past conversations and learn preferences, alongside higher rate limits for Deep Think. New releases kept arriving, from Liquid AI’s open‑weight vision–language models designed for speed on consumer devices and Tencent’s Hunyuan‑Vision‑Large appearing near the top of public multimodal leaderboards to Higgsfield AI’s Draw‑to‑Video for steering video output with sketches. Personnel changes continued as Igor Babuschkin left xAI to launch an investment firm and Anthropic acquired the co‑founders and several staff from Humanloop, an enterprise AI evaluation and safety platform.
Google’s own showcase underlined how phones and homes are becoming canvases for AI features. The Pixel 10 line placed Gemini across the range with visual overlays for the camera, a proactive cueing assistant, tools for call translation and message handling, and features such as Pixel Journal. Tensor G5, built by TSMC, brought a reported 60 per cent uplift for on‑device AI processing. Gemini for Home promised more capable domestic assistance, while Fitbit and Pixel Watch 4 introduced conversational health coaching and Pixel Buds added head‑gesture controls. Against that backdrop, Google published details on Gemini’s environmental footprint, claiming the model consumes energy equivalent to watching nine seconds of television per text request and “five drops of water” per query, while saying efficiency improved markedly over the past year. Researchers challenged the framing, arguing that indirect water used by power generation is under‑counted and calling for comparable, third‑party standards. Elsewhere in search and productivity, Google expanded access to an AI mode for conversational search, and agreements emerged to push adoption in public agencies at low unit pricing.
Attention also turned to compact models and devices. Google released Gemma 3 270M, an ultra‑compact open model that can run on smartphones and browsers while eking out notable efficiency, with internal tests reporting that 25 conversations on a Pixel 9 Pro consumed less than one per cent of the battery and quick fine‑tuning enabling offline tasks such as a bedtime story generator. Anthropic broadened access to its Learning Mode, which guides people towards answers rather than simply supplying them, and now includes an explanatory coding mode. On the hardware side, HTC introduced Vive Eagle, AI glasses that allow switching between assistants from OpenAI and Google via a “Hey Vive” command, with on‑device processing for features such as real‑time photo‑based translation across thirteen languages, an ultra‑wide camera, extended battery life and media capture, currently limited to Taiwan.
Behind many deployments sits a familiar requirement: secure, compliant handling of data and a disciplined approach to roll‑out. Case studies from large industrial players point to the bedrock steps that enable scale. Lockheed Martin’s work with IBM on watsonx began with reducing tool sprawl and building a unified data environment capable of serving ten thousand engineers; the result has been faster product teams and a measurable boost in internal answer accuracy. Governance frameworks for AI, including those provided by vendors in security and compliance, are moving from optional extras to prerequisites for enterprise adoption. Organisations exploring agentic systems in particular will need clear approval gates, auditing and defaults that err on the side of caution when sensitive actions are in play.
Broader infrastructure questions loomed over these developments. Analysts projected that AI hyperscalers may spend around $2.9 trillion on data centres through to 2029, with a funding gap of about $1.5 trillion after likely commitments from established technology firms, prompting a rise in debt financing for large projects. Private capital has been active in supplying loans, and Meta recently arranged a large facility reported at $29 billion, most of it debt, to advance data centre expansion. The scale has prompted concerns about overcapacity, energy demand and the risk of rapid obsolescence, reducing returns for owners. In parallel, Google partnered with the Tennessee Valley Authority to buy electricity from Kairos Power’s Hermes 2 molten‑salt reactor in Oak Ridge, Tennessee, targeting operation around 2030. The 50 MW unit is positioned as a step towards 500 MW of new nuclear capacity by 2035 to serve data centres in the region, with clean energy certificates expected through TVA.
Consumer and enterprise services pressed on around the edges. Microsoft prepared lightweight companion apps for Microsoft 365 in the Windows 11 taskbar. Skyrora became the first UK company licensed for rocket launches from SaxaVord Spaceport. VIP Play announced personalised sports audio. Google expanded availability of its Imagen 4 model with higher resolution options. Former Twitter chief executive Parag Agrawal introduced Parallel, a startup offering a web API designed for AI agents. Deutsche Telekom launched an AI phone and tablet integrated with Perplexity’s assistant. Meta faced scrutiny after reports about an internal policy document describing permitted outputs that included romantic conversations with minors, which the company disputed and moved to correct.
Healthcare illustrated both promise and caution. Alongside the space‑medicine assistant, the antibiotics work and NASA’s solar model, a study reported that routine use of AI during colonoscopies may reduce the skill levels of healthcare professionals, a finding that could have wider implications in domains where human judgement is critical and joining a broader conversation about preserving expertise as assistance becomes ubiquitous. Practical guides continued to surface, from instructions for creating realistic AI voices using native speech generation to automating web monitoring with agents that watch for updates and deliver alerts by email. Bill Gates added a funding incentive to the medical side with a $1 million Alzheimer’s Insights AI Prize seeking agents that autonomously analyse decades of research data, with the winner to be made freely available to scientists.
Apple’s plans added a longer‑term note by looking beyond phones and laptops. Reports suggested that the company is pushing for a smart‑home expansion with four AI‑powered devices, including a desktop robot with a motorised arm that can track users and lock onto speakers, a smart display and new security cameras, with launches aimed between 2026 and 2027. A personality‑driven character for a new Siri called Bubbles was described, while engineers are reportedly rebuilding Siri from scratch with AI models under the codename Linwood and testing Anthropic’s Claude as a backup code-named Glenwood. Alongside those ambitions sit nearer‑term updates. Apple has been preparing a significant Siri upgrade based on a new App Intents system that aims to let people run apps entirely by voice, from photo edits to adding items to a basket, with a testing programme under way before a broader release and accuracy concerns prompting a limited initial rollout across selected apps. In the background, Tim Cook pledged to make all iPhone and Apple Watch cover glass in the United States, though much of the production process will remain overseas, and work on iOS 26 and Liquid Glass 1.0 was said to be nearing completion with smoother performance and small design tweaks. Hiring currents persist as Meta continues to recruit from Apple’s models team.
Other platforms and services added their own strands. Google introduced Personal Context for Gemini to remember chat history and preferences and added temporary chats that expire after seventy‑two hours, while confirming a duplicate event feature for Calendar after a public request. Meta’s Threads crossed 400 million monthly active users, building a real‑time text dataset that may prove useful for future training. Funding news continued as Profound raised $35 million to build an AI search platform and Squint raised $40 million to modernise manufacturing with AI. Lighter snippets appeared too, from a claim that beards can provide up to SPF 21 of sun protection to a report on X that an AI coding agent had deleted a production database, a reminder of the need for careful sandboxing of tools. Gaming‑style benchmarks surfaced, with GPT‑5 reportedly earning eight badges in Pokémon Red in 6,000 steps, while DeepSeek’s R2 model was said to be delayed due to training issues with Huawei’s Ascend chips. Senators in the United States called for a probe into Meta’s AI policies following controversy about chatbot outputs, reports suggested that the US government was exploring a stake in Intel, and T‑Mobile’s parent launched devices in Europe featuring Perplexity’s assistant.
Perhaps the most consequential lesson from the period is simple. Progress in capability is rapid, as competition results, research papers and new features attest. Yet adoption is being steered by human factors: the preference for a known voice, the desire for choice and control, and understandable scepticism when new modes do not perform as promised on day one. GPT‑5’s early missteps forced a course correction that restored a familiar option and increased transparency around limits and modes. The agentic turn is showing real value in constrained workflows, but still benefits from patience and supervision. Architecture debates are converging on combinations rather than replacements. And amid bold bids, public quarrels, hefty capital outlays and cautionary studies on enterprise returns, the work of making AI useful, safe and dependable continues, one model update and one workflow at a time.
The critical differences between Generative AI, AI Agents, and Agentic Systems
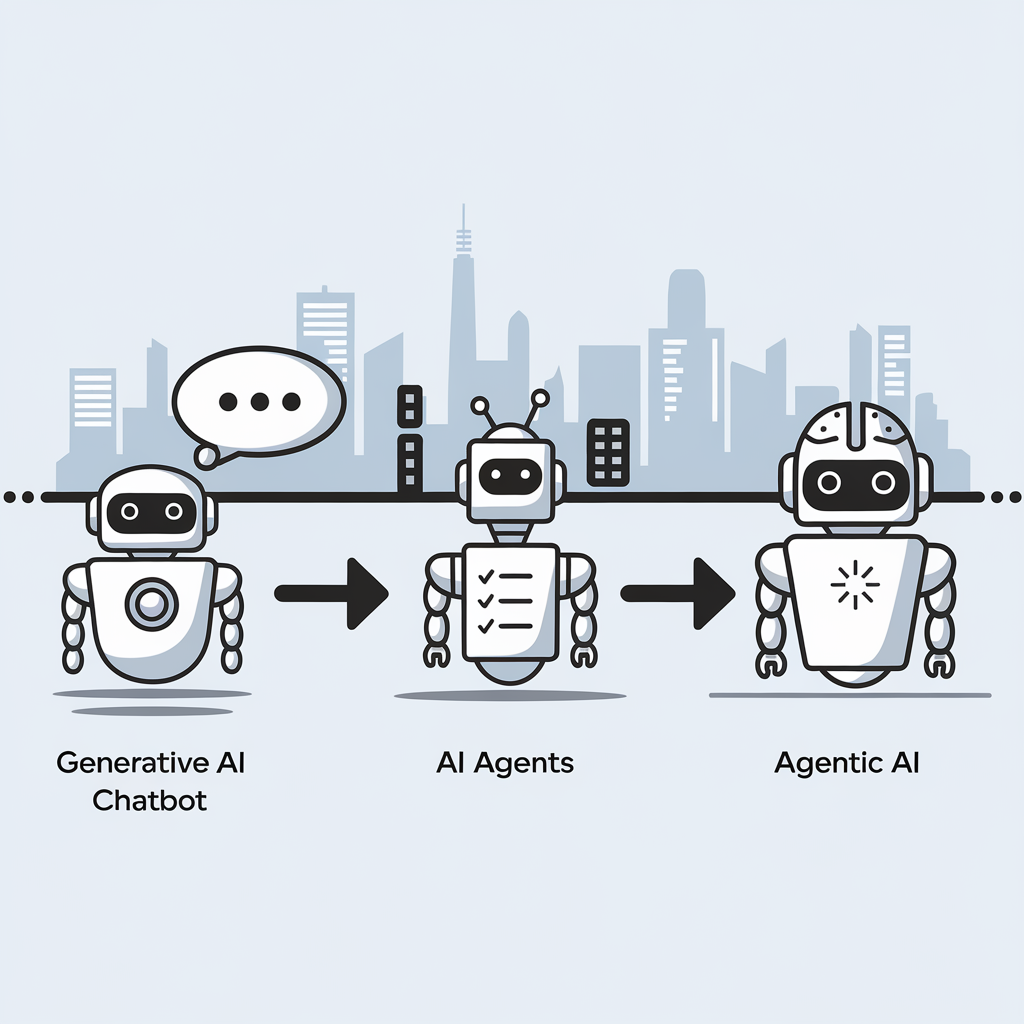
The distinction between three key artificial intelligence concepts can be explained without technical jargon. Here then are the descriptions:
- Generative AI functions as a responsive assistant that creates content when prompted but lacks initiative, memory or goals. Examples include ChatGPT, Claude and GitHub Copilot.
- AI Agents represent a step forward, actively completing tasks by planning, using tools, interacting with APIs and working through processes independently with minimal supervision, similar to a junior colleague.
- Agentic AI represents the most sophisticated approach, possessing goals and memory while adapting to changing circumstances; it operates as a thinking system rather than a simple chatbot, capable of collaboration, self-improvement and autonomous operation.
This evolution marks a significant shift from building applications to designing autonomous workflows, with various frameworks currently being developed in this rapidly advancing field.
Claude Projects: Reusing your favourite AI prompts
Some things that I do with Anthropic Claude, I end up repeating. Generating titles for pieces of text or rewriting text to make it read better are activities that happen a lot. Others would include the generation of single word previews for a piece or creating a summary.
Python or R scripts come in handy for summarisation, either for a social media post or for introduction into other content. In fact, this is how I go much of the time. Nevertheless, I found another option: using Projects in the Claude web interface.
These allow you to store a prompt that you reuse a lot in the Project Knowledge panel. Otherwise, you need to supply a title and a description too. Once completed, you just add your text in there for the AI to do the rest. Title generation and text rewriting already are set up like this, and keywords could follow. It is a great way to reuse and refine prompts that you use a lot.
Finding human balance in an age of AI code generation
Recently, I was asked about how I felt about AI. Given that the other person was not an enthusiast, I picked on something that happened to me, not so long ago. It involved both Perplexity and Google Gemini when I was trying to debug something: both produced too much code. The experience almost inspired a LinkedIn post, only for some of the thinking to go online here for now. A spot of brainstorming using an LLM sounds like a useful exercise.
Going back to the original question, it happened during a meeting about potential freelance work. Thus, I tapped into experiences with code generators over several decades. The first one involved a metadata-driven tool that I developed; users reported that there was too much imperfect code to debug with the added complexity that dealing with clinical study data brings. That challenge resurfaced with another bespoke tool that someone else developed, and I opted to make things simpler: produce some boilerplate code and let users take things from there. Later, someone else again decided to have another go, seemingly with more success.
It is even more challenging when you are insufficiently familiar with the code that is being produced. That happened to me with shell scripting code from Google Gemini that was peppered with some Awk code. There was no alternative but to learn a bit more about the language from Tutorials Point and seek out an online book elsewhere. That did get me up to speed, and I will return to these when I am in need again.
Then, there was the time when I was trying to get a Julia script to deal with Google Drive needing permissions to be set. This started Google Gemini into adding more and more error checking code with try catch blocks. Since I did not have the issue at that point, I opted to halt and wait for its recurrence. When it did, I opted for a simpler approach, especially with the gdrive CLI tool starting up a web server for completing the process of reactivation. While there are times when shell scripting is better than Julia for these things, I added extra robustness and user-friendliness anyway.
During that second task, I was using VS Code with the GitHub Copilot plugin. There is a need to be careful, yet that can save time when it adds suggestions for you to include or reject. The latter may apply when it adds conditional logic that needs more checking, while simple code outputting useful text to the console can be approved. While that certainly is how I approach things for now, it brings up an increasingly relevant question for me.
How do we deal with all this code production? In an environment with myriads of unit tests and a great deal of automation, there may be more capacity for handling the output than mere human inspection and review, which can overwhelm the limitations of a human context window. A quick search revealed that there are automated tools for just this purpose, possibly with their own learning curves; otherwise, manual working could be a better option in some cases.
After all, we need to do our own thinking too. That was brought home to me during the Julia script editing. To come up with a solution, I had to step away from LLM output and think creatively to come up with something simpler. There was a tension between the two needs during the exercise, which highlighted how important it is to learn not to be distracted by all the new technology. Being an introvert in the first place, I need that solo space, only to have to step away from technology to get that when it was a refuge in the first place.
For anyone with a programming hobby, they have to limit all this input to avoid being overwhelmed; learning a programming language could involve stripping out AI extensions from a code editor, for instance, LLM output has its place, yet it has to be at a human scale too. That perhaps is the genius of a chat interface, and we now have Agentic AI too. It is as if the technology curve never slackens, at least not until the current boom ends, possibly when things break because they go too far beyond us. All this acceleration is fine until we need to catch up with what is happening.
Automating writing using R and Claude
Automation of writing using AI has become prominent recently, especially since GPT came to everyone's notice. It is more than automation of proofreading but of producing the content itself, as Mark Hinkle and Luke Matthews can testify. Figuring out how to use Generative AI needs more than one line prompts, so knowing what multi-line ones will work is what is earning six digit annual salaries for some.
Recently, I gave this a go when writing a post that used content from a Reddit post thread. The first step was to extract the content from the thread, and I found that I could use R to do this. That meant installing the RedditExtractoR package using the following command:
install.packages("RedditExtractoR")
Then, I created a short script containing the following lines of code with placeholders added in place of the actual locations:
library("RedditExtractoR")
write.csv(get_thread_content("<URL for Reddit post thread>"), "<location of text file>")
The first line above calls the RedditExtractoR package for use so that its get_thread_content function could be used to scape the thread's textual content. This was then fed to write.csv for writing out a text file with content.
Once I had the text file, I could upload it to Anthropic's Claude for the next steps. Firstly, I got it to give me a summary of the thread discussion before I asked it to give me the suggested solutions to the issue. Impressively, it capably provided me with the latter.
Now armed with these answers, I set to crafting the post from them. Claude did not do all the work for me, but it certainly helped with the writing. This is something that I fancy exploring further, especially given how business computing is likely to proceed in the next few years.
OWASP Top 10 for Large Language Model Applications
OWASP stands for Open Web Application Security Project, and it is an online community dedicated to web application security. They are well known for their Top 10 Web Application Security Risks and late last year, they added a Top 10 for
Large Language Model (LLM) Applications.
Given that large language models made quite a splash last year, this was not before time. ChatGPT gained a lot of attention (OpenAI also has had DALL-E for generation of images for quite a while now), there are many others with Anthropic Claude and Perplexity also being mentioned more widely.
Figuring out what to do with any of these is not as easy as one might think. For someone more used to working with computer code, using natural language requests is quite a shift when you no longer have documentation that tells what can and what cannot be done. It is little wonder that prompt engineering has emerged as a way to deal with this.
Others have been plugging in LLM capability into chatbots and other applications, so security concerns have come to light, so far, I have not heard anything about a major security incident, but some are thinking already about how to deal with AI-suggested code that others already are using more and more.
Given all that, here is OWASP's summary of their Top 10 for LLM Applications. This is a subject that is sure to draw more and more interest with the increasing presence of artificial intelligence in our everyday working and no-working lives.
LLM01: Prompt Injection
This manipulates an LLM through crafty inputs, causing unintended actions by the LLM. Direct injections overwrite system prompts, while indirect ones manipulate inputs from external sources.
LLM02: Insecure Output Handling
This vulnerability occurs when an LLM output is accepted without scrutiny, exposing backend systems. Misuse may lead to severe consequences such as Cross-Site Scripting (XSS), Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), privilege escalation, or remote code execution.
LLM03: Training Data Poisoning
This occurs when LLM training data are tampered, introducing vulnerabilities or biases that compromise security, effectiveness, or ethical behaviour. Sources include Common Crawl, WebText, OpenWebText and books.
LLM04: Model Denial of Service
Attackers cause resource-heavy operations on LLMs, leading to service degradation or high costs. The vulnerability is magnified due to the resource-intensive nature of LLMs and the unpredictability of user inputs.
LLM05: Supply Chain Vulnerabilities
LLM application lifecycle can be compromised by vulnerable components or services, leading to security attacks. Using third-party datasets, pre-trained models, and plugins can add vulnerabilities.
LLM06: Sensitive Information Disclosure
LLMs may inadvertently reveal confidential data in its responses, leading to unauthorized data access, privacy violations, and security breaches. It’s crucial to implement data sanitization and strict user policies to mitigate this.
LLM07: Insecure Plugin Design
LLM plugins can have insecure inputs and insufficient access control. This lack of application control makes them easier to exploit and can result in consequences such as remote code execution.
LLM08: Excessive Agency
LLM-based systems may undertake actions leading to unintended consequences. The issue arises from excessive functionality, permissions, or autonomy granted to the LLM-based systems.
LLM09: Overreliance
Systems or people overly depending on LLMs without oversight may face misinformation, miscommunication, legal issues, and security vulnerabilities due to incorrect or inappropriate content generated by LLMs.
LLM10: Model Theft
This involves unauthorized access, copying, or exfiltration of proprietary LLM models. The impact includes economic losses, compromised competitive advantage, and potential access to sensitive information.